Word Embeddings Under the Hood: How Neural Networks Learn from Language
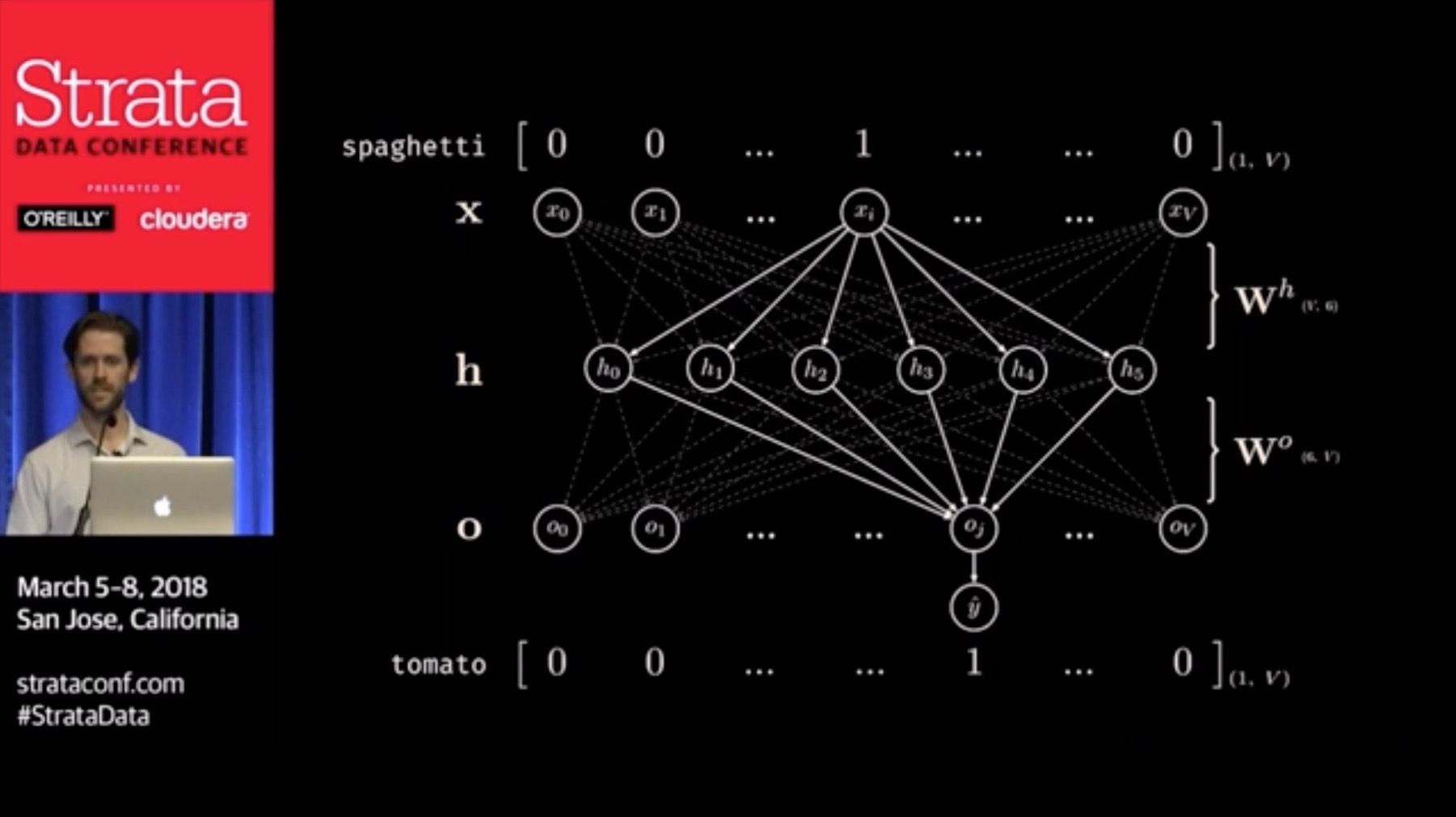
I had the opportunity to present the talk Word Emdbeddings Under the Hood: How Neural Networks Learn from Language at the Strata Data Conference in San Jose. This talk aims to provide a clear explanation from first principles about how neural networks learn rich vector representations for words. Along the way, we get a “minimum viable introduction” to the fundamental concepts of how neural networks work, including neurons, activation functions, neural network layers, loss functions, gradient descent, the backpropagation algorithm, and more.
The slides from the talk are available below.
This post was originally published on datatheoretic.com.