Analytics Panel Discussion with Pittsburgh Data Science

I was happy to join the Pittsburgh Data Science Group for a panel discussion about how local technology leaders are applying advanced analytics within their teams and businesses. My fellow panelists were Lucky Pamula, Head of Cognitive Automation at PNC Bank, and Christopher Stephens, VP of Data Technology at American Eagle Outfitters. We had a great turnout, and I enjoyed the conversation!
I’d like to offer special thanks to the PGH Data Science organizers for inviting me and to Microsoft for hosting us at their office in downtown Pittsburgh.
This post was originally published on datatheoretic.com.
Creating a Next-Generation Financial Dataset from Scratch with NLP and Active Learning
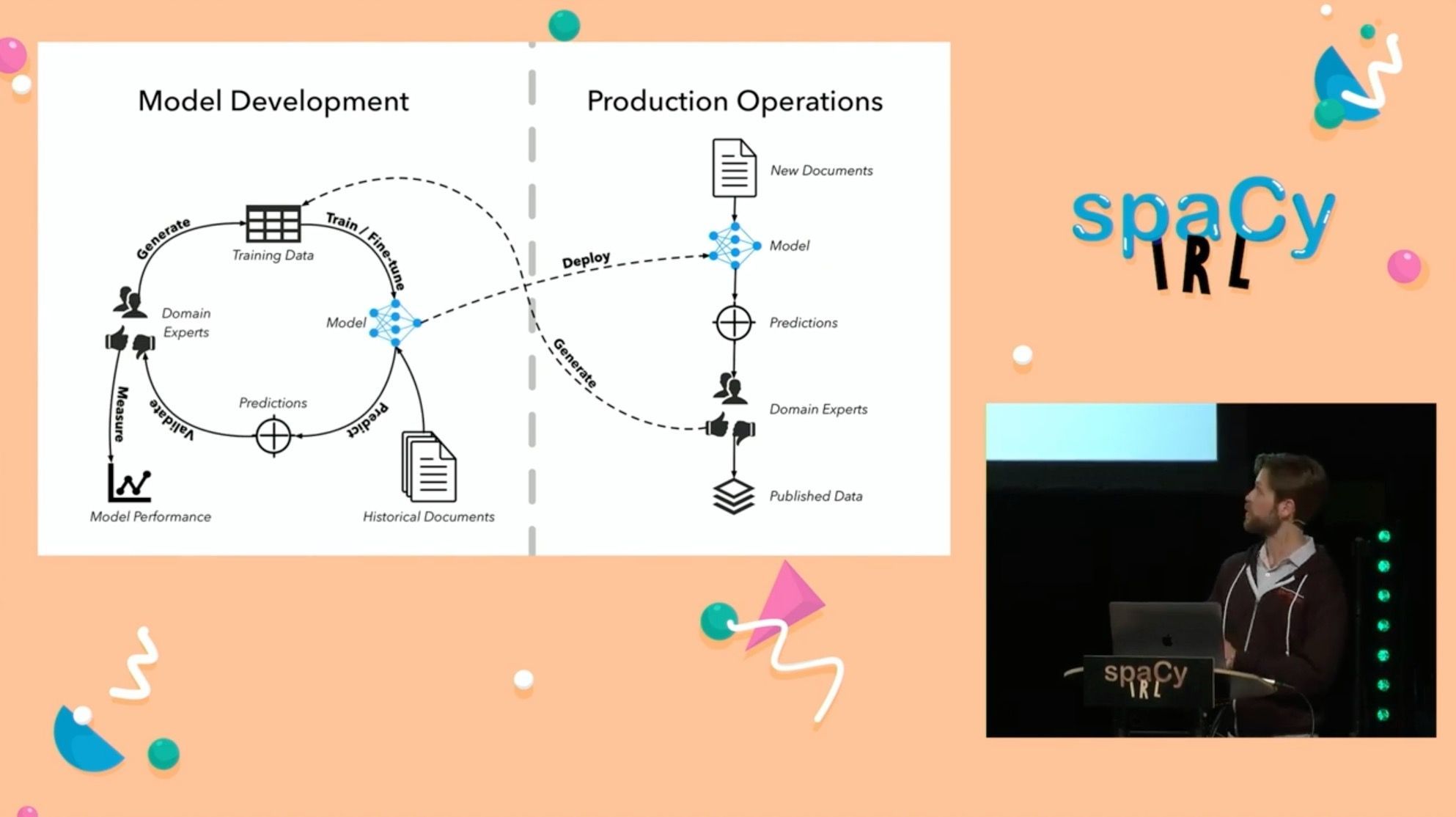
I was delighted to be invited to give a talk at the inaugural spaCy IRL conference in Berlin, Germany. spaCy IRL was a gathering of researchers and practitioners pushing the boundaries of industrial-strength natural language processing with the spaCy software library and ecosystem.
My talk highlighted one of my group’s projects: using natural language processing and active learning to create a new kind of financial intelligence data. The goal was to assemble a dataset about companies’ environmental, social, and governance practices (“ESG”). We used a human-in-the-loop workflow to iteratively train and validate machine learning models to detect mentions of companies’ ESG practices from publicly-available documents. Check out the video to learn more about our methodology.
The slides from the talk are available below.
This post was originally published on datatheoretic.com.
Managing Data Science in the Enterprise

Josh Poduska, Chief Data Scientist at Domino Data Lab, and I teamed up to deliver the talk Managing Data Science in the Enterprise at the Strata Data Conference in New York. We talked about the obstacles that prevent many companies from succeeding with data science, how to manage data science as an organizational capability, the data science project lifecycle, common organization structures for data science teams, and more.
Take a look at the slides from our talk below!
This post was originally published on datatheoretic.com.
Facilitating Data Science Collaboration and Faster Innovation: Panel Discussion

I was honored to serve as a panelist for the discussion Facilitating Data Science Collaboration and Faster Innovation as part of the inaugural Rev Data Science Leaders Summit at the Yerba Buena Center for the Arts in San Francisco.
I joined Elena Grewal, Head of Data Science at Airbnb, Sivan Aldor-Noiman, Head of Data Science and Data Engineering at Wellio, and moderator Nancy Hersh, founder of Applied Analytics, to talk about ideas for accelerating data science progress at startups, tech companies, and established enterprises. Check out our conversation in the video below!
This post was originally published on datatheoretic.com.
Word Embeddings Under the Hood: How Neural Networks Learn from Language
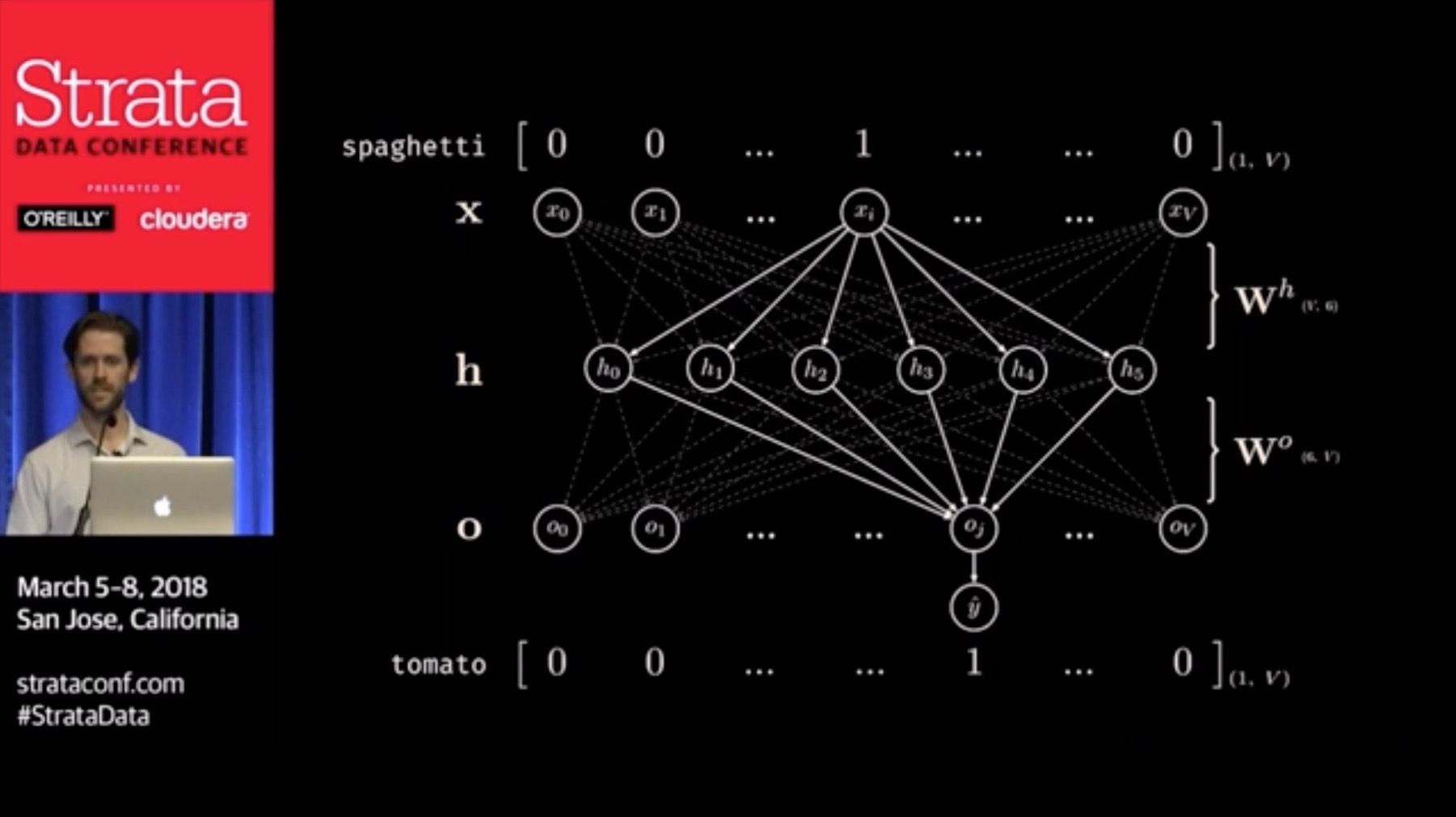
I had the opportunity to present the talk Word Emdbeddings Under the Hood: How Neural Networks Learn from Language at the Strata Data Conference in San Jose. This talk aims to provide a clear explanation from first principles about how neural networks learn rich vector representations for words. Along the way, we get a “minimum viable introduction” to the fundamental concepts of how neural networks work, including neurons, activation functions, neural network layers, loss functions, gradient descent, the backpropagation algorithm, and more.
The slides from the talk are available below.
This post was originally published on datatheoretic.com.
Modern NLP in Python at PyData DC
I had the pleasure of presenting the tutorial Modern NLP in Python at PyData DC. This 90-minute tutorial provides an overview of powerful tools and modeling techniques used for natural language processing in Python, including spaCy, gensim, statistical phrase detection, Latent Dirichlet Allocation (LDA), and word vector embedding with word2vec. I demonstrate the utility of each tool and technique using relatable examples from the excellent Yelp Dataset, a publicly-available dataset of business profiles, customer reviews, and related metadata provided by the business search and rating service Yelp.
You can find the Jupyter notebook from the tutorial on GitHub and view it online with Jupyter nbviewer. I recommend nbviewer because it preserves the interactive visualizations in the notebook.
This post was originally published on datatheoretic.com.